
Data Science: Multimodal learning is revolutionizing artificial intelligence by enabling models to process and integrate information from various modalities such as text, images, audio, and video. This interdisciplinary approach enhances the capability of AI systems to understand complex interactions and generate more accurate predictions.
Professionals enrolling in classes are increasingly being introduced to multimodal learning techniques, ensuring they stay at the forefront of this cutting-edge field. A data scientist course in Hyderabad provides hands-on exposure to integrating multiple data types, preparing learners to build robust AI models that mimic human-like comprehension.
Understanding Multimodal Learning
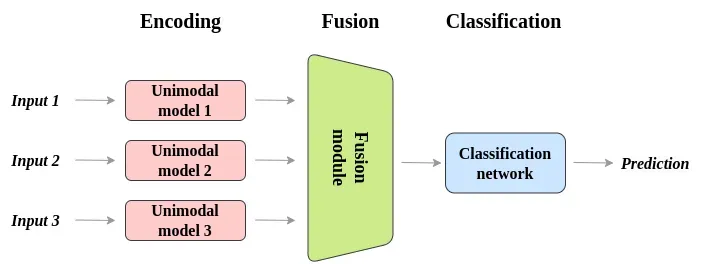
Multimodal learning refers to the ability of AI systems to process and interpret multiple data sources simultaneously. Unlike traditional unimodal models that rely on a single type of data, multimodal systems leverage diverse inputs to improve decision-making and accuracy. For instance, a self-driving car integrates camera images, LiDAR data, GPS information, and audio signals to navigate safely. Similarly, chatbots use both textual and vocal cues to enhance human-machine interactions. A course in Hyderabad introduces learners to multimodal deep learning, covering essential techniques such as fusion strategies, attention mechanisms, and data alignment.
Key Components of Multimodal Learning
Multimodal learning relies on several core components to ensure seamless integration of diverse data types. Understanding these components is crucial for AI practitioners looking to advance their expertise through a course in Hyderabad.
Feature extraction is a crucial step where each modality undergoes a unique process to transform raw data into meaningful representations. Image data uses a convolutional neural network (CNN)-based extraction, while textual data relies on transformers such as BERT. Data alignment is necessary since different modalities often operate on distinct timescales, requiring techniques like cross-modal attention mechanisms to synchronize data streams effectively.
Fusion techniques play a fundamental role in combining multiple data sources efficiently. Early fusion involves concatenating features at the input level, late fusion aggregates outputs from separate models, and hybrid fusion combines both approaches to enhance performance. Cross-modal learning enables AI models to transfer knowledge across different modalities, allowing a model trained on textual data to interpret images using shared embedding spaces.
Multimodal representation learning ensures AI systems develop unified representations that encapsulate information from multiple modalities, facilitated by advanced architectures like transformer-based fusion models.
Applications of Multimodal Learning (Data Science)
Multimodal learning has numerous real-world applications, and many of these are explored in the data scientist course. Professionals who undertake a course gain practical knowledge on implementing multimodal AI across various industries.
In healthcare and medical diagnostics, AI-powered diagnostic tools integrate imaging, genetic, and textual patient data to improve disease detection accuracy. For instance, cancer detection models use MRI scans, pathology reports, and patient history to provide reliable diagnoses. Additionally, multimodal AI is being used to enhance medical imaging analysis, where different imaging modalities such as X-rays, CT scans, and MRIs are combined to improve diagnostic accuracy.
Autonomous vehicles depend on multimodal learning to process visual feeds, LiDAR data, and real-time audio cues for safe driving decisions. Advanced AI models interpret multiple sensory inputs simultaneously, reducing accidents and enhancing navigation capabilities. These self-driving systems also incorporate traffic signal recognition and environmental awareness models to make better real-time decisions.
Virtual assistants and chatbots have evolved with multimodal learning, allowing speech recognition systems to integrate textual, vocal, and facial expression data to improve human-machine communication. This enables AI-driven conversations to become more natural and effective. Smart home assistants use these techniques to respond to both voice commands and contextual visual data, improving user experiences.
Sentiment analysis and emotion recognition benefit significantly from multimodal AI. By analyzing text, voice tone, and facial expressions, AI systems detect emotions more accurately, playing a crucial role in customer service, mental health assessments, and personalized marketing strategies. Businesses leverage multimodal sentiment analysis to tailor their services based on customer moods and preferences.
Video content analysis is another key application, where multimodal AI enhances the analysis of video data by integrating visual, audio, and textual metadata. This technology is widely used for automatic captioning, video summarization, and detecting inappropriate content on social media platforms. Law enforcement agencies also use video analytics combined with voice recognition for crime detection and forensic analysis.
Fraud detection in finance relies on multimodal AI models to analyze multiple forms of data simultaneously. Financial institutions integrate transaction history, voice authentication, and biometric verification to build robust fraud detection systems that minimize security risks. AI-driven cybersecurity solutions use multimodal learning to detect potential threats by analyzing network activity, user behavior, and contextual data.
Challenges in Multimodal Learning
Despite its advantages, multimodal learning presents several challenges. Professionals enrolling in the course gain insights into these challenges and learn strategies to overcome them.
Data heterogeneity arises because different data modalities vary in structure, quality, and size, making it difficult to integrate them effectively. Mismatches in resolution, sampling rates, and noise levels can degrade performance. Researchers are exploring advanced normalization techniques to bridge these differences and improve model accuracy.
Computational complexity is another major hurdle, as processing and aligning multimodal data require significant computational resources, demanding high-end hardware and optimized algorithms. Cloud-based AI solutions and distributed computing techniques are increasingly being used to mitigate this issue, making multimodal learning more accessible.
Data scarcity is a limitation since high-quality multimodal datasets are often difficult to obtain, restricting the training potential of AI models. Synthetic data generation and data augmentation strategies are being explored to create larger, more diverse datasets that enhance the robustness of multimodal models.
Model interpretability remains a challenge, as understanding how multimodal AI models arrive at decisions is critical for ensuring transparency and trustworthiness in AI applications. Researchers are developing explainable AI (XAI) techniques that visualize how different modalities contribute to model decisions, helping stakeholders understand AI predictions.
Future of Multimodal Learning
Multimodal learning is expected to play a transformative role in the evolution of AI. Researchers are continuously improving fusion techniques, transformer-based architectures, and self-supervised learning methods to enhance multimodal AI systems. Professionals trained in a data scientist course in Hyderabad will be at the forefront of these advancements, helping shape the next generation of AI-driven innovations.
Self-supervised learning is emerging as a game-changer, enabling AI systems to learn representations from unlabeled data across multiple modalities. Advances in generative AI are also contributing to multimodal learning by synthesizing new data types, improving model robustness. Future AI systems will be capable of reasoning across modalities, creating more human-like interactions in areas such as education, entertainment, and virtual simulations.
As AI continues to evolve, the demand for expertise in multimodal learning will grow significantly. The fusion of multiple data modalities promises breakthroughs in AI capabilities, leading to more intelligent, human-like systems specifically capable of understanding and interacting with the world in a holistic manner. Those who master multimodal learning will be at the forefront of AI-driven innovation, shaping the future of artificial intelligence across industries.
ExcelR – Data Science, Data Analytics and Business Analyst Course Training in Hyderabad
Address: Cyber Towers, PHASE-2, 5th Floor, Quadrant-2, HITEC City, Hyderabad, Telangana 500081
Phone: 096321 56744

